Physicians are not losing evenings to documentation because the technology does not exist. They are losing them because the tools they have been handed do not tell the whole story about what those accuracy numbers actually mean for a real 20-patient day.
The AI medical transcription accuracy figures circulating in 2026, 93%, 98%, and even 99.9%, are real. They are also, without context, almost useless to a physician trying to decide whether a clinical documentation tool is safe enough to trust. This article explains what the numbers mean, where they hold, where they do not, and what a physician should evaluate before adopting any AI-powered medical documentation platform.
What AI Medical Transcription Accuracy Numbers Actually Measure
Most AI transcription accuracy figures measure word error rate (WER), the percentage of words the model gets right against a reference transcript. A 93% accuracy figure means that 7 of every 100 words are wrong. In a 15-minute clinical encounter, that is not a small number.
The more important distinction is what kind of errors occur. A 2025 study published in NEJM AI confirmed that omissions are the dominant error type in AI-generated clinical notes, not mistranscriptions. Separately, a narrative review covering 18 studies found omissions accounted for 86.3% of all errors in AI-generated documentation. The AI is more likely to leave something out than to state something wrong.
For clinical documentation accuracy, this distinction matters operationally. A wrong word is easy to catch on review. A missing dosage change, a dropped symptom, or an omitted lab result in the assessment section requires the physician to reconstruct what happened from memory, and that is where documentation errors have downstream consequences.
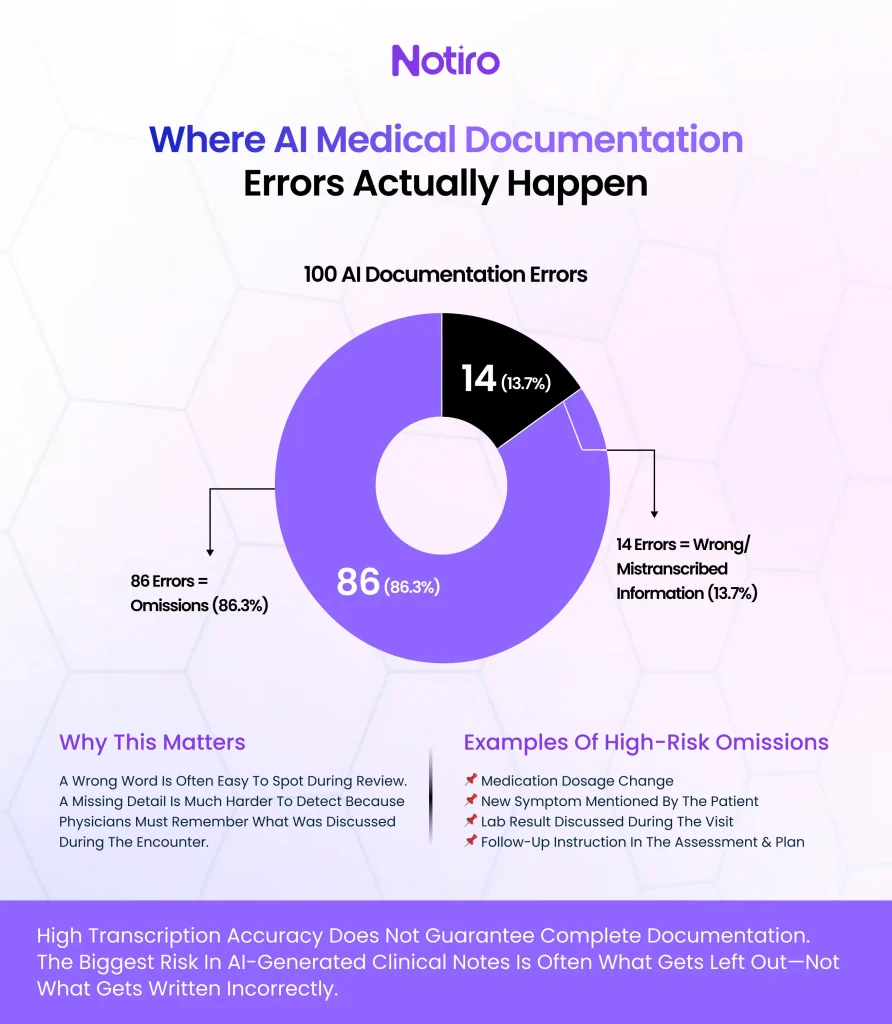
Why Accuracy Varies Across Clinical Settings
Controlled dictation environments routinely achieve WERs below 1%. Real exam rooms produce something different. A 2025 evaluation published in JMIR Human Factors tested six AI scribes across standardized 15-minute encounters and found none were consistently error-free. Factors that degraded accuracy included multiple speakers, background noise, and extraneous conversations, the standard conditions in most outpatient settings.
Specialty-specific language compounds this. General medical AI transcription software trains on broad clinical datasets. A family medicine visit with multi-problem presentations, hypertension, diabetes management, and an incidental skin concern in a single appointment stresses any model that was not trained on that specific conversational structure. Radiology terminology, psychiatry language, and pediatric encounters each carry vocabulary and pacing that general-purpose models handle inconsistently.
Healthcare transcription technology built for clinical settings addresses this differently than general-purpose speech recognition. Models tuned on specialty-specific corpora reduce error rates on domain vocabulary. Speechmatics’ 2025 medical model reported 50% fewer errors on medical terms than general-purpose alternatives. The gap between a general transcription engine and a medically tuned one is measurable in real clinical settings.
The ICD-10 Problem That Transcription Accuracy Alone Cannot Solve
This is the accuracy gap that most coverage on AI transcription misses entirely. A note that is 95% transcriptionally accurate can still generate the wrong billing code, or no billing code at all, if the system does not convert clinical language into ICD-10 and CPT codes automatically.
ICD-10 has over 70,000 codes. CPT has over 10,000. Physicians selecting codes manually at the end of a full clinic day, under time pressure, consistently select lower-complexity codes than those supported by the visit. This is not a knowledge failure; it is a systems failure. The documentation was accurate. The coding was not.
Automated medical transcription that stops at the note level leaves this gap open. Clinical documentation accuracy must extend beyond the transcript into the billing layer to have a real revenue impact for a practice. Platforms like Notiro address this by auto-suggesting ICD-10 and CPT codes drawn directly from the visit audio and the generated note, so the physician reviews suggested codes rather than constructing them from memory after a 12-patient morning. Most AI scribe competitors, including Freed AI, Heidi Health, and Nabla, do not offer this. The note gets written; the coding remains manual.
What the Productivity Research Shows
A 2025 UCSF study published in JAMA Network Open found that physicians using AI scribes generated approximately $3,044 more in revenue per year and saw approximately 0.8 more patients per week than non-users. A separate study from Mass General Brigham documented a 21.2% reduction in burnout scores after 84 days of AI scribe use. The AMA reported in 2025 that over 40% of US physicians were already using AI documentation tools.
The first randomized controlled trial of an ambient AI scribe, published in NEJM AI in 2025, found a 9.5% reduction in time spent in the note compared to the control group. That is a meaningful reduction, but it is notably smaller than the 60–70% time savings some vendor marketing has claimed. Physicians evaluating AI transcription software should ask vendors for study design details, not headline figures.
What the research consistently confirms is that the review step cannot be skipped. Clinician sign-off before any AI-generated note is entered into the chart is not optional. The JMIR evaluation found that all six tested scribes produced “good to excellent” quality notes, but none were error-free. Reviewing for completeness, especially in the assessment and plan sections, remains the physician’s responsibility regardless of transcription accuracy rate.
Notiro is built around this clinical reality. The ambient scribe captures the visit and generates a structured note in SOAP, H&P, or POMR format. The physician reviews and finalizes before chart sync. That workflow does not remove the clinician from the loop, it removes the hours of manual documentation that should never have fallen on a physician’s time in the first place.
How to Evaluate AI Medical Transcription Accuracy for a Real Practice
The number to ask vendors about is not their peak accuracy in controlled conditions. It is their word error rate in multi-speaker encounters with background noise, the conditions that describe most outpatient exam rooms. Ask specifically how the system handles:
Medication names spoken quickly. The JMIR evaluation identified dosage changes and medication terms as among the categories most prone to omission. A physician whose patient reports stopping a beta-blocker during a busy visit needs that captured in the note.
Multi-problem presentations. A single visit covering three clinical problems requires contextual separation in the note. A model that conflates the chronic disease management section with the acute complaint is not accurate, even if its WER is low.
EHR delivery. AI transcription accuracy means nothing if the note requires manual reentry. Healthcare transcription technology that syncs directly to the chart, through verified EHR integration rather than copy-paste, is the final step that makes the time savings real.
The Metric That Actually Predicts Clinical Utility
Transcription accuracy is a floor condition, not a ceiling. A platform that achieves 90% word accuracy in real clinical conditions is worth evaluating. One that achieves 90% only in a quiet studio setting is not usable in practice.
The metric that predicts clinical utility is the combination of transcription accuracy, note completeness, coding automation, and EHR delivery in actual clinical conditions. AI healthcare documentation that improves all four, and allows a physician to close a chart before the next patient walks in, is what the research and the clinical need actually point to.
The physicians reporting the highest satisfaction from AI-powered medical documentation tools in 2026 are not the ones whose vendors claimed the highest accuracy numbers. They are the ones whose tools reduced the distance between the visit and the closed chart, handled the billing codes they used to construct manually, and got out of the way.
Try Notiro
Documentation burden costs physicians an average of 3 or more hours per day, time that compounds into burnout, reduced capacity, and missed revenue (AMA, multiple studies). Notiro automates the full clinical day: patient intake before the visit, ambient scribing during it, and ICD-10 and CPT code suggestions from the visit audio before the chart closes. Start your free trial at notiro.ai, no IT setup, no enterprise contract.